被低估的先进封装巨头
过去谈到英特尔,大家可能常说他们在制造方面落后,但其实在先进方面,英特尔在过去几年已经取得了不错的成绩。
我们将始终拨回到2025年9月,当时英伟达CEO黄仁勋做了一件看似毫无道理的事——向英特尔承诺投资50亿美元。在分析人士看来,这笔钱不是用于晶圆制造,也不是用于工艺技术,而是用于封装。
全球市值最高的半导体公司,其GPU几乎为全球所有人工智能数据中心提供动力,审视了英特尔(一家股价接近十年低点、代工部门每季度亏损数十亿美元、晨星评级为“无护城河”的公司),并决定开出一张足以收购4%至5%股权的支票。后续,黄仁勋层告诉媒体,英特尔拥有“Foveros的多技术封装能力,这在这里确实至关重要”。
人们的第一反应自然是困惑。英特尔?那家在制程节点上落后了十年的公司?那家连首席财务官自己都承认其代工厂客户的承诺订单量“微不足道”的公司?

几十年来,半导体行业衡量进步的唯一标准就是晶体管密度。更小的制程意味着更快、更便宜、更高效的芯片。企业的成败取决于其缩小制程的能力。英特尔在这场竞赛中领先了40年,但在2015年前后遭遇重挫,台积电趁机夺得了霸主地位。
但就在大家关注制程节点竞赛的时候,发生了这样的事:芯片变得如此复杂,以至于没有哪个单一的制程节点能够完美地满足现代处理器的所有功能。CPU核心需要最快的晶体管来保证原始时钟频率;GPU阵列需要高密度和高能效来应对并行工作负载;而I/O控制器、内存接口、安全引擎呢?它们几乎无法从尖端晶体管中获得任何提升,而且即便如此,它们的制造成本仍然高得惊人。在3nm制程下,设计一颗芯片的成本就超过5亿美元。
想象一下盖房子。你可以用结构钢来搭建整个房子的框架,包括壁橱和花园小屋。或者,你也可以只在关键部位(承重墙)使用钢材,其他地方则使用木材。效果一样,成本却低得多。这个比喻与基于芯片的设计非常契合:只将最先进(也最昂贵)的工艺节点用于那些真正需要的组件,而其他所有组件则使用更便宜、更成熟的工艺节点来制造。
因此,问题不在于谁拥有最好的晶体管,而在于谁能最好地将来自多个来源的异质硅集成到一个可用的单一产品中。
芯片是如何不再扁平的
在深入了解英特尔的具体技术之前,你需要掌握三个概念。理解它们只需要大约九十秒,但它们将为你理解后续所有内容奠定基础。
概念一:芯粒
芯粒(chiplet)顾名思义,就是一个功能单一的小型芯片,设计用于与其他封装内的小型芯片连接。它不像传统的单芯片设计那样使用一块巨大的硅芯片来处理所有功能,而是将设计拆分成多个功能模块,例如 CPU 模块、GPU 模块、I/O 模块和内存控制器模块。每个模块都可以采用最适合其功能的工艺节点进行制造,然后组装在一起。
方案二:2.5D和3D封装
芯粒之间需要相互通信。在 2.5D 封装中,芯粒并排排列在共享基板上,通过微型桥接器横向连接。英特尔称其版本为 EMIB。可以把它想象成建造相邻的房屋,并用有顶走廊连接起来。在 3D 封装中,芯粒垂直堆叠,彼此面对面。英特尔称之为 Foveros。这就像在楼上建造公寓楼层,楼层之间有电梯井连接。连接更短、更密集、速度更快,但由于散热空间减少,工程难度也更大。
概念3:混合键合
过去连接堆叠芯片的方法是使用称为微凸点的微小焊球。想象一下,将一块乐高积木的底部浸入焊锡中,然后将其压到另一块积木上。这种方法虽然可行,但在小尺寸下使用焊锡会造成混乱。混合键合技术则完全摒弃了焊锡。它将两个芯片上的铜焊盘直接接触,并通过表面化学反应和热退火工艺进行键合。铜原子扩散穿过界面,形成一条连续的金属路径。
英特尔的Foveros Direct技术实现了9微米间距(每平方毫米约12,000个连接),每比特功耗低于0.05皮焦耳。芯片内通信的功耗约为每比特0.1皮焦耳。混合键合技术已经突破了一个临界点,使得芯片间连接在实际应用中与单个芯片内部连接一样高效。
这将彻底改变芯片设计的计算方式。
七年五代更新
自 2018 年以来,英特尔的 Foveros 技术经历了五代发展演变。每一代都解决了前代技术的特定局限性,最终实现了互连密度提高 30 倍,能源效率提高 3 倍。
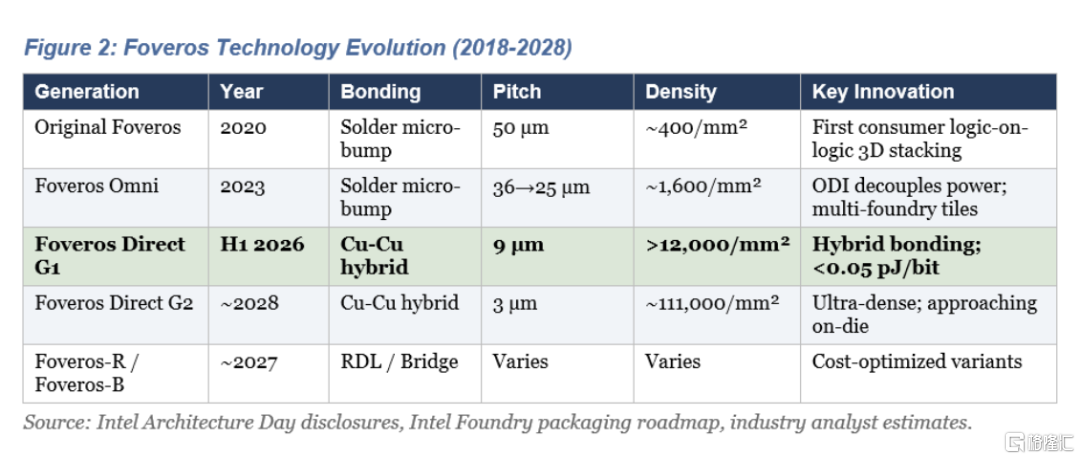
最初的 Foveros (2020 年,Lakefield 公司)是概念验证:50 微米焊料微凸点,每平方毫米约 400 个凸点,每比特功耗 0.15 皮焦耳。它将一个 10 纳米计算芯片面朝下键合到一个 22 层 I/O 芯片上。虽然功能正常,但这种通过芯片供电的方式会产生干扰,限制了间距的进一步缩小。
Foveros Omni (2023 年,Meteor Lake 架构)通过全向互连 (ODI) 技术解决了这个问题,该技术通过围绕基片的铜柱来供电。可以将其理解为增加了外部防火通道,使内部楼梯间仅供行人通行。这种解耦设计使得混合使用来自不同代工厂的芯片成为可能。芯片间距缩小至 36 微米,并正朝着 25 微米迈进。
Foveros Direct (预计2026年上半年在Clearwater Forest工厂生产)实现了代际飞跃:采用铜对铜混合键合技术,间距为9微米,互连密度超过12,000个/平方毫米,功耗低于0.05皮焦/比特。第二代产品目标是在2027-2028年左右实现3微米间距(约111,000个/平方毫米)。英特尔声称,其流体自对准贴装技术可将吞吐量提升10倍。
两种成本优化变体完善了产品组合:Foveros-R (更便宜的 RDL 中介层)和Foveros-B (RDL 加上局部硅桥),两者的目标都是在 2027 年左右投产。

Panther Lake
四个工艺、两个工厂,一个封装
理论固然美好,但产品上市才是关键。英特尔酷睿Ultra系列3的Panther Lake处理器将于2025年底开始出货,并于2026年1月全面上市。它将来自两家代工厂四个不同制程节点的芯片集成到单个封装中。

为什么要将GPU的生产分散到两家代工厂?因为经济因素迫使我们这样做。台积电的N3E芯片在处理更大规模的并行工作负载时,能够提供更高的密度和效率。据报道,Intel在大尺寸芯片的成本上不具备竞争力,但这种小型GPU芯片可以作为英特尔代工厂GPU制造经验的学习平台。最终结果是:Panther Lake超过70%的芯片面积由英特尔自主研发,这与Lunar Lake和Arrow Lake的情况截然不同。
这就是混合架构理念的现实化体现。每个功能都使用最佳节点,无论其开发者是谁。

让单芯片结构过时的数学
假设每平方毫米芯片的缺陷率为0.1%,那么100平方毫米的芯片良率约为90.5%。而400平方毫米的芯片良率仅为67%左右。在5纳米工艺下,对于800平方毫米的单芯片SoC而言,缺陷成本占总制造成本的50%以上。

Clearwater Forest 将这种逻辑发挥到了极致:12 个小型 Intel 18A 芯片(每个芯片 24 个核心)混合粘合到 3 个基础芯片上,外加 2 个 I/O 芯片。总共 17 个芯粒,每个芯粒在组装前都可以单独测试。

I/O模块在不同产品代际间可以沿用。Clearwater Forest沿用了Xeon的I/O模块。Panther Lake在同一平台上提供了不同的GPU配置。AMD通过MI300A和MI300X展示了这一点:在同一封装平台上,用GPU芯片替换了CPU芯片。
位于新墨西哥州里奥兰乔的英特尔Fab 9工厂是美国唯一一家能够大规模生产3D先进封装芯片的高产能工厂。目前,在台积电亚利桑那州工厂制造的芯片必须运往台湾进行封装。英特尔副总裁马克·加德纳证实,英特尔已“将采用台积电CoWoS技术的产品直接移植到我们的Foveros技术上,完全没有进行任何设计更改。”
良率、成本、速度、供应链韧性,每一项都有利于分散化。它们共同构筑了一道结构性护城河。
当 47个tiles汇聚成一个封装

Foveros负责垂直堆叠,EMIB负责横向连接。单插槽即可实现超过5TB/s的内存带宽和petaFLOPS级的AI性能。

三位竞争者,各有优势。
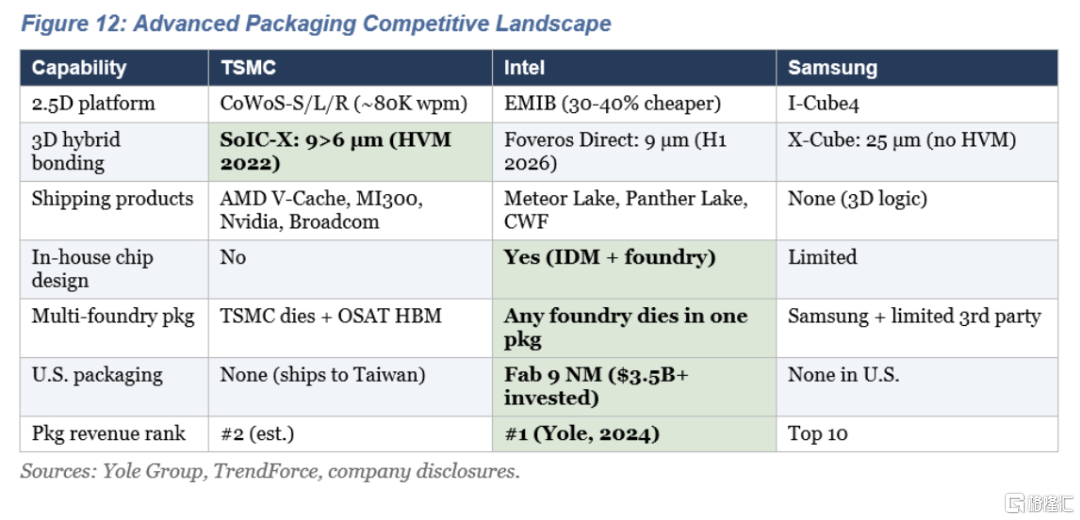
台积电在产能方面占据主导地位。CoWoS芯片预计在2025年底达到每分钟8万片的产能,目标是在2026年底达到每分钟13万片。英伟达占据了约60%的份额。SoIC混合键合技术自2022年开始出货。产能领先优势为3-4年。
AMD 使用了台积电的产品组合,但也承担了单一供应商的风险。V -Cache 的密度是 2D 芯片的 200 倍。MI300 是一款拥有 1530 亿个晶体管的加速器。但 AMD 完全依赖于单一供应商。
三星在部署方面落后。尚未推出商用3D混合键合逻辑芯片。目标是在2026年实现4微米以下的制程。代工厂市场份额仅为5.9%,而台积电则高达35.3%。

封装作为代工厂的入口。

供需关系十分严峻。台积电的CoWoS项目已排满至2026年。台积电亚利桑那工厂生产的芯片必须运往台湾进行封装。英特尔则提供了另一种选择:位于美国新墨西哥州Fab 9工厂的先进封装技术(投资超过35亿美元)。UCIe标准(由英特尔发起,拥有100多家支持者,UCIe 3.0的传输速率为64 GT/s)使芯片互连不再依赖于代工厂,从而真正实现了封装即服务。
市场规模:目前为 460 亿美元,到 2030 年将达到 800 亿美元。

封装已经从后台的附属品变成了战略武器。资本支出说明了一切。
接下来的规划
Diamond Rapids 的目标是在 2026 年中后期推出:最多 192 个 Panther Cove P 核心,支持 PCIe 6.0、CXL 3,TDP 为 500-650W。直接竞争对手是 AMD EPYC Venice(Zen 6,台积电 2nm)。
据报道, Nova Lake (2026 年下半年)的计算单元已在台积电 N2 芯片上完成流片。即使 18A 芯片日趋成熟,英特尔仍将继续采用混合代工厂模式。
2025 年 12 月的概念演示展示了一种尺寸超过光刻胶尺寸 12 倍的设计:Intel 14A 上有 16 个计算单元,18A-PT 上有 8 个基础单元,24 个 HBM5 堆叠,面积接近 10,296 平方毫米。封装,而不是光刻技术,决定了系统层面的可能性。

总结
过去十年,市场对英特尔的评价一直局限于单一视角:制程技术的执行力。而就这一指标而言,英特尔的表现并不尽如人意。10nm工艺的延误、7nm工艺的挫折、以及失去苹果公司,都印证了这一点。
但这种说法假设制造优势仅仅取决于晶体管密度。事实并非如此。至少现在不是了。2026 年的关键问题是:谁能从任何来源获取硅,以近乎零性能损失的方式将其堆叠成三维结构,并在单个封装中交付一个可用的系统?
英特尔是地球上唯一一家能够同时做到这一切的公司。
台积电生产最好的晶体管,并在混合键合工艺量产方面领先,但它并不设计芯片。AMD设计的芯片非常出色,但完全依赖单一供应商。三星有发展晶圆代工的雄心,但目前还没有商用的3D混合键合逻辑产品。英伟达设计了世界上最重要的AI加速器,但在制造和封装方面都必须依赖其他供应商。
英特尔设计芯片,自主生产,拥有最广泛的封装产品组合,为外部代工厂封装芯片,并运营着美国唯一的高产能3D封装工厂。这种良性循环已经开始运转:内部产品验证了封装技术的成熟度,成熟的产品吸引了外部客户,每个客户都分摊了研发成本,更优的经济效益为下一代产品的研发提供了资金。
秉持学术诚信,就必须以钢铁般的意志力来应对反对意见。以下就是一位聪明的对手会提出的论点。
台积电的产能领先优势是实实在在的。三到四年的混合键合产品出货经验意味着其良率学习能力、客户信任度和供应链成熟度,而这些都是英特尔尚未获得的。等到英特尔实现量产时,台积电可能已经领先两代产品了。
英特尔的执行记录令人质疑。Clearwater Forest 项目从2025年推迟到2026年上半年。英特尔晶圆代工业务每季度亏损数十亿美元。首席财务官承认外部业务量“微不足道”。晨星公司给予英特尔“无护城河”评级。
良率复利是一把双刃剑。单独来看,小块tile的优势在数学上可能并不明显,尤其是在组装损失率较高的情况下。

对英特尔而言,他们无需在封装方面超越台积电,只需达到足够好、供应充足且位于合适的国家即可。CoWoS 的瓶颈是结构性的,而非暂时的。而且,美国封装所面临的地缘政治压力正在加剧,而非减弱。
我们认为,有三件事值得关注:

谬误一:Clearwater Forest 的良率报告。如果英特尔在 2026 年下半年之前无法在 17 芯片架构上实现经济可行的良率,那么封装护城河理论将受到实质性削弱。密切关注出货量、平均售价趋势以及 Diamond Rapids 的进度信号。
谬误二:外部客户数量。英伟达的交易要到2027年底才能交付。如果英特尔在2026年底前无法宣布至少两项价值数十亿美元的额外封装协议,那么这个论点进展太慢。CoWoS的限制窗口并非永久性的。
谬误三:台积电在亚利桑那州的封装。如果台积电将先进封装技术引入亚利桑那州,英特尔的地域优势将大幅缩小。密切关注台积电的资本支出披露。
客观的结论是:英特尔打造了一款真正独一无二的产品。Foveros Direct 近乎芯片级的性能、Panther Lake 久经考验的混合晶圆代工架构、英伟达的认证以及美国本土制造,都是实实在在的优势。
但资产并不等同于优势。优势需要多年而非几个季度的持续执行才能获得。英特尔拥有所需的工具,也拥有源源不断的客户,市场也迫切需要它的产品。然而,它尚未展现出那种将战略地位转化为竞争护城河的、枯燥乏味却又无比卓越的运营能力。
封装已经准备就绪。问题是英特尔是否也准备好了。
格隆汇声明:文中观点均来自原作者,不代表格隆汇观点及立场。特别提醒,投资决策需建立在独立思考之上,本文内容仅供参考,不作为实际操作建议,交易风险自担。


